I have graylog and elasticsearch deployed in kuberenetes. Three graylog nodes as cluster and three elasticsearch with 1 master and two master eligible nodes. The spec of the worker nodes is 64 core and 128gb ram and 20TB disk on each worker node. We are getting 2tb logs per day. Logs are coming from kuberentes cluster and other applications each with differnet size. Right now Iam only getting 7000 message output per sec so getting around 20 to 25k messages processed per second but the input rate is 20k to 100k per second so most of the messages are going to journal with millions of unprocessed messages and Iam unable to view the logs from the dashboard most of the time.
The CPU usage of the graylog and elasticsearch is low so I am unable to figure out the bottleneck here…
Graylog leader and elasticsearch master is on dedicated workernodes and the remaining are on shared workernodes.
Please help I want to use all my cpu resources and increase the processing to 100k message per second. What elase I need to do add more data nodes but the current servers are underutilized. What iam missing here need assistance
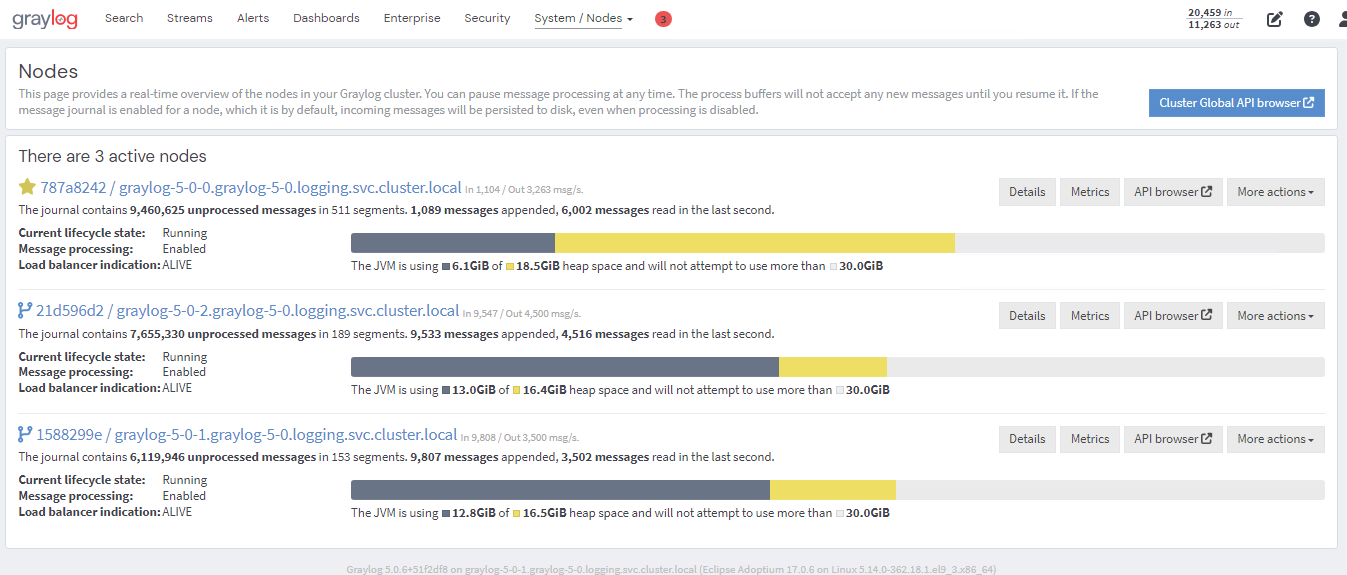
Can you post a screenshot of the nodes page of each of thr graylog nodes from system>nodes its helpful to have a look at the journals and buffers on each node.
Each graylog node is processing only 3000 to 7000 message per second but when I checked my cpu usage it only take 20% and also elasticsearch not taking system resources eventhough it have 64 core and 128gb ram. How much nodes and spec is needed to process without unprocessed messages in this case
did you change the number of your processors?
Have a look at the server config:
processbuffer_processors = ?
outputbuffer_processors = ?
inputbuffer_processors = ?
the sum of those three should be approx the number of cores of the node.
The value of output_batch_size is also tunable.
Is adding more elasticsearch nodes increase the output rate?
Also is dedicated master and data nodes needed in elasticsearch
Right now I have three elasticsearch nodes with no dedicated roles each with128gb ram and 64core
32gb JVM for graylog and elasticcsearch. Planning to deploy multiple elasticsearch instance on the same worker node beacuse the CPU and memory usage right now is very low
How much gl and elasticnode is reccomended for processing 100k message per second. Daily getting around 2TB logs with 7 day retention
What kind of disk do you have in your ES nodes? From your initial message, I would guess magnetic disks, and this is definitely not recommended with ES.
All the official docs recommend SSDs for (at least) the hot tier. And based on personal experience, trying to use magnetic disks will lead to them getting overwhelmed very quickly. Especially considering that your ingestion rate is not that low.
To answer your other questions:
adding ES nodes may increase the processing rate. But in your case, if you are adding nodes on the same physical hardware, on the same disks which are already hitting their limit, you will probably not see a benefit
dedicated master/data nodes are not a requirement in this case. You only have three nodes, so you should be fine for now
I agree with you: your Graylog is not the bottleneck, I am very sure it’s OpenSearch:
your outputbuffer is full → either not enough output-processors (not the case) or not enough power to process the logs on the OpenSeach-End. The flow out of Graylog should therefore be good → it must be OpenSearch.
@bogd asked a very good question: what kind of disks/ssd do you have for OpenSearch? IO is very important here, and magnetic drives will not deliver for that scale.
Can you run a iotop on your OpenSearch? How much IO is it doing, and how high are the IO waits? You might also run “top” to see your IO waits, as you can read here.
We are using SSD disks
We tried to deploy multiple instance of ES and the processing improved.
How much JVM to assign to es nodes also any sharding reccomendations. We are using 20+ shards now
is 12GB enough for ES nodes? we are deploying 10 es nodes with 12gb each