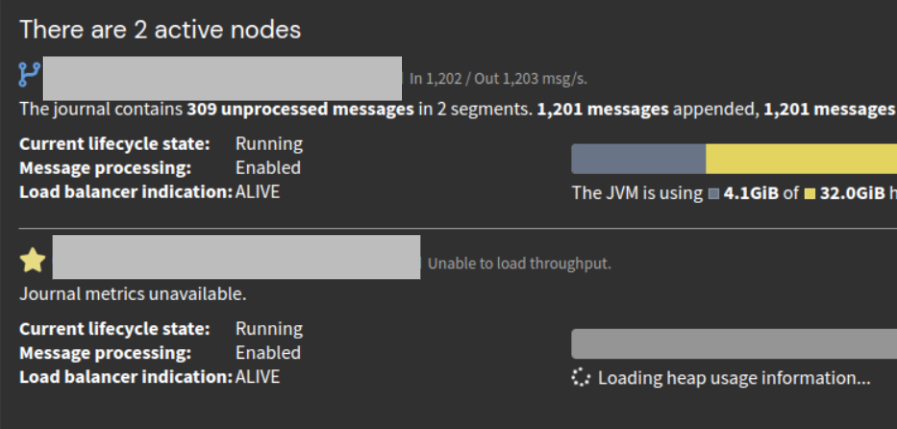
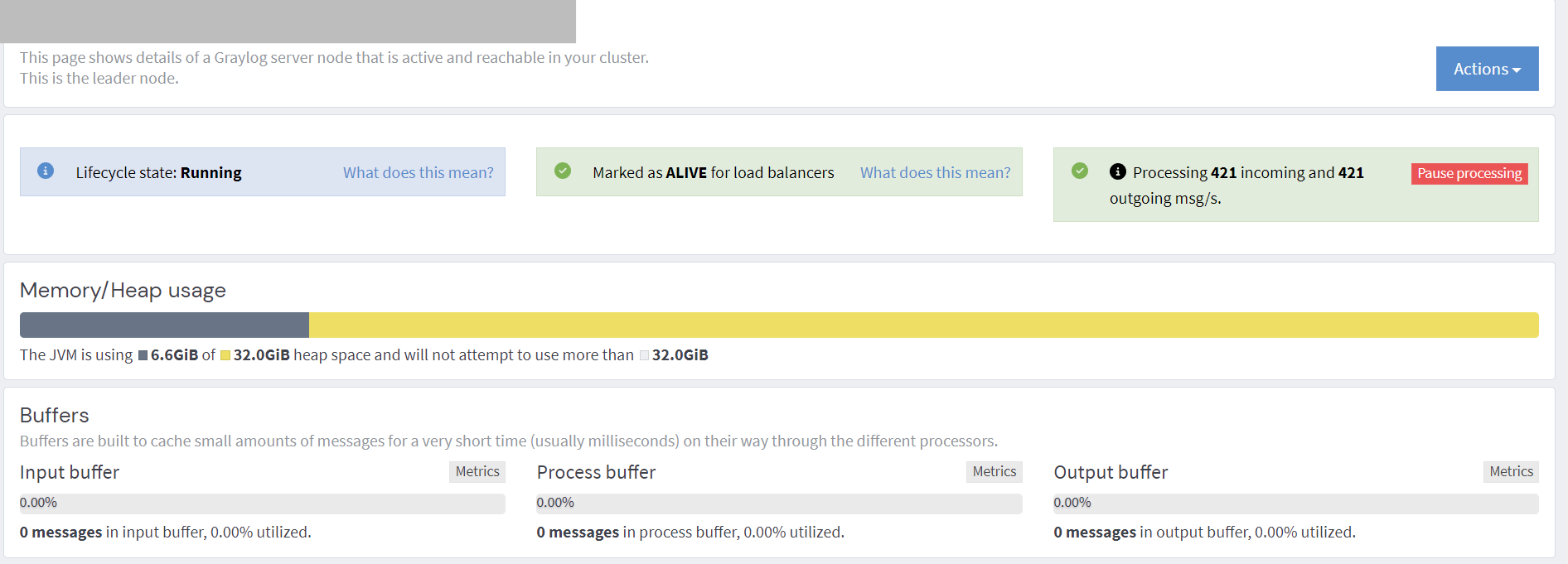
Hello everyone. I have a problem that information about one node disappears from time to time. Everything seems to be working correctly, I don’t see any errors in the logs. But this error occurs when I want to see what’s wrong with node.
Getting plugins on node “xxxxxxx” failed: FetchError: There was an error fetching a resource: Internal Server Error. Additional information: timeout
This error occurs every minute, and sometimes it changes the state of the node. The cluster has 2 greylog servers and 5 elasticsearch servers. I checked the availability of everyone, from each server. But I can’t find the error.
OS - Debian 11
Graylog Server - 5.2.4-1
Elasticsearch - 7.10.2
As far as I understand, which parameter can be increased is related to the timeout. Sometimes it just doesn’t have time to open information about the node.
I checked the tcpmdump. There are no problems with the network. I think it has to do with performance maybe.
The error was related to the http_bind_address parameter. This parameter was configured to 0.0.0.0, and due to the fact that both hosts have the same docker subnet 172.0.0.1 - the REST API transport address was the same.