Hello. I installed graylog (4.30) in a TrueNas jail and connected my firewall.
To make that work, I defined an input and a stream and did write and copied about 25 extractors. And that works OK, however three things did surprise me very much, but perhaps that is due to my limited knowledge. The reason for this post
My extractor queue is like thins:
some generic extractors e.g. to extract the task name
one or more extractors for messages related to program-A
one or more extractors for messages related to program-B
etc.
However I am missing three things:
If the one or more extractors related to program-A did their job, and the incoming message was related to Program-A
So I would expect an “extractor queue ready exit” option. There is no reason to walk over the rest of the extractors !!!
If a certain extractor matches, it could imply that I am not interested in that given message
So I would expect an “drop message” option
It could be that if a certain extractor matches, I would like to assign a certain value to a field which is not at all part of the message
So I would expect an option to fill a field with an 'extractor defined value
I assume others did met this as well, so I am curies how others dialed with this issues / idea’s
From my experience the messages extractors are not the best way for extracting, the pipelines are much more powerful. As far as I know extractors will be deprecated some time in the future, but there is no date or version yet.
I am learning, however. You are promoting pipelines however … I have ‘some’ problems:
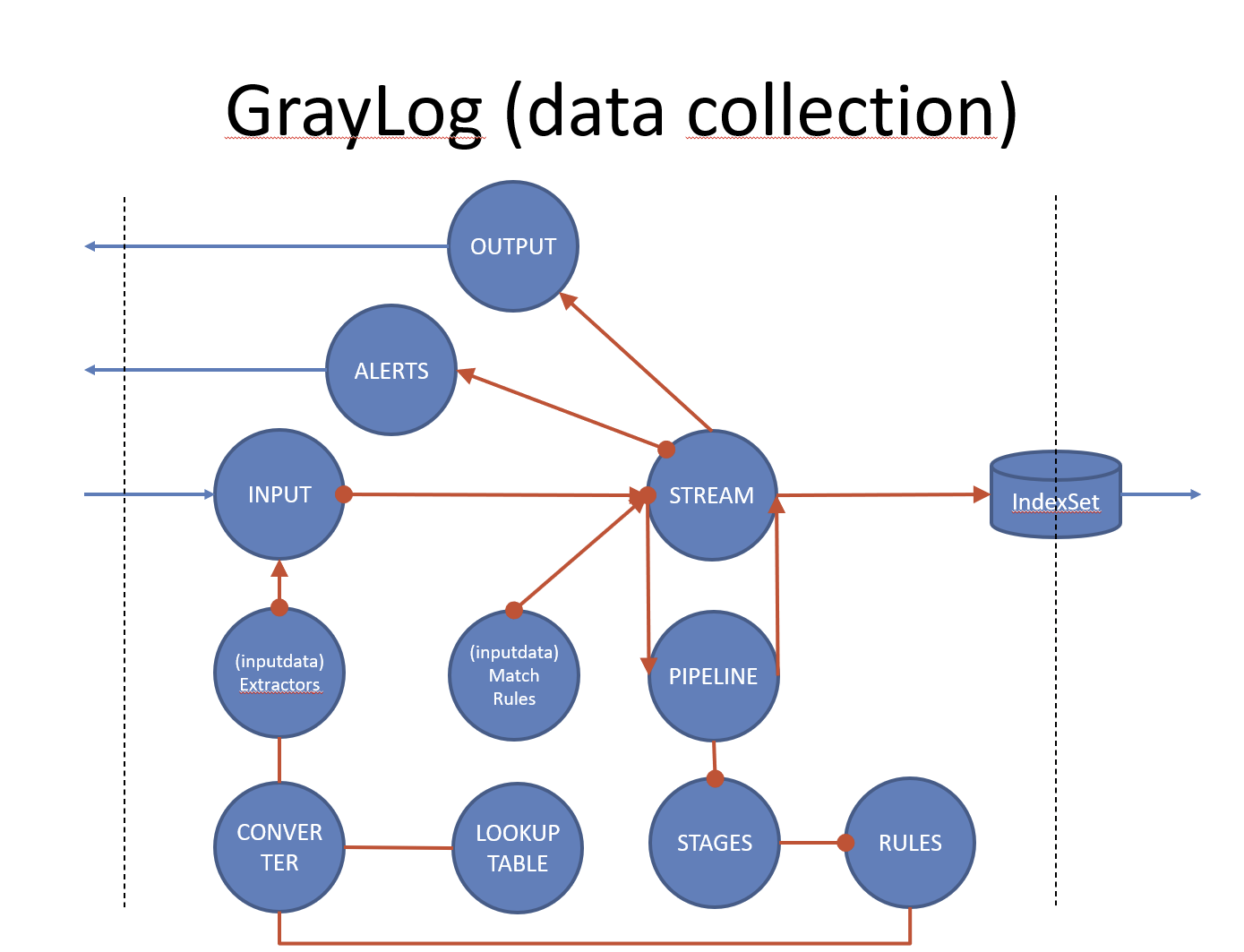
I am missing a picture showing about the graylog architecture. How function blocks like inputs, steams, extractors etc. are interconnected. If you know such a picture … please share it
pipelines seems to be more powerfull than extractors but also not as easy to use
I am not aware of a function which can convert extractors into a pipeline
In point one 1) you suggest an check on a field as solution, that is what I do within the extractors, I was looking for something like “break” (I am done leave the pipeline / return from the pipeline function)
I did read somewhere about a filter function, but I can not find such an function of “processing block” in the collection ^architecture^
I did read somewhere that you can define the order in which function blocks are processed, no idea how to do that (or is that an enterprise feature perhaps)
I agree pipelines are not easy. There are tons of examples in this forum on HowTo’s , configurations, routing, re-naming, filtering messages, also use regex/Grok within the pipeline, etc…
Also in this forum. BUT if I understand this correct, the function of this extractor, then how to make a pipeline the same way, OR magically turn the Extractor into a pipeline?
Example #1
let’s say you have an Input for Linux devices, and you need to route a message that has a unique field “node_02” into another stream and send out an alert.
rule " alert"
when
has_field("node_02")
then
route_to_stream(id:"63094a92218139114d4923f2");
end
I tend to use stream ID’s instead of stream names.
Example #2
let’s say you have an Input for Linux devices, and you need to route a message that has a unique field “node_02” with specific data under that field call “Louis” into another stream and send out an alert.
rule “Route Node_02/Louis”
when
has_field("node_02") AND contains(to_string($message.node_02, "Louis")
then
route_to_stream(id:"63094a92218139114d4923f2");
end
Not only will you find example here in the forum but also in GitHub, there are Tag’s" here in the forum you can use for better search. Pipelines are so versatile I cant post all configurations here.
Dropping message.
Example#3
rule "discard Message with Louis"
when
has_field("node_02") AND contains(to_string($message.node_02), "Louis", true)
then
drop_message();
end
@louis don’t take this the wrong way but these statements tell me you not really interested in Pipeline, probably because you don’t have enough knowledge.
If you get stuck and need assistants, I’m sure someone here can help.
EDIT:
I forgot to add about Extractors, depending on what your trying to achieve you can create a REGEX extractor and attach a lookup table to it.
Here is one of mine, extractor type regular expression
I will probably look into pipelines later, but what is really strikes me is that I do not see any drawing clearly shows the graylog processflow and related how the different objects (input, extractors, streams, pipelines etc.) are interconnected! Which is the first thing you need to know, if you want to use “graylog” in the best possible way.
input is clear (the data arrives here)
output is clear (data towards other systems)
index is clear (the message storage DB)
also clear extractors (identifying messages and extracting fields from messages arriving from one particular input)
dashboard (representing data as available in the DB)
However the rest and the interaction between the blocks …
The link I posted above does show a logical diagram on the flow. This was help from multiple community members that collaborated because the question that’s being asked here was asked before.
Going back over your topics again to make sure I understand what your trying to achieve.
Extractors and how they work from the beginning.
Select a message input on the System → Inputs page and hit Manage extractors in the actions menu. You can also choose to apply so called converters on the extracted value to convert a string consisting of numbers to an integer or double value. So Let’s say you have 25 extractors using default configurations, meaning something like this.
Set a plan on what you want, its pretty simple flow
INPUT --> modifying data here --> STREAM (filters or routing) --> INDEX.
That’s all I have for you, also in those links I post above, if you scroll down the page you will notice another member have posted video link on this subject and/or check out Graylog YouTube channel. Just a thought.