but the problem is that i have an index size in total of 4.7 or 4.8 TB, and my total cluster size is 6 TB, with 3 data node servers with each 2TB.
every data node server has an LVM, so the logs of elasticseach and the data they go to that LVM. my log files are around 8.4 GB, but the elastic data should have been deleting previous indices as configured in graylog.
the thing is that i’m running this environment for months and nothing like that ever happen… and i’m a little bit surprised. i have read the forums and nothing similar appears in my searchers…
on an elastic forum people were talking about a similar thing where the data folder of elastichsearch gets full without any reason, and some recommended to upgrade the elastichsearch… the problem is that graylog 2.4 can go for 6th version of elastic.
i’ll keep looking into this, and if i’ll find out what is the cause i’ll let you know.
you placed more information in your second post than in your first!
It might be helpful to describe what had happened, exactly - like to someone who is not you, not knowing anything about your environment. Than it is more likely that you get some help.
Did you have enabled or disabled the force_merge after index rotation? How is your index retention and rotation strategy? How is your sharding and replica configuration? How is your daily ingest? Did the data volumen got full or did something like the logfile fill the disk?
The way the information are presented is nothing that would help someone who invest his spare time to help to find the problem in your environment - all information might be given and present but the way it is presented make it hard to read and combine.
Check the elastic config for data dir settings, and the ES API too on all servers.
I find this at your logs.
Xfs mark 5% of disk, and you have only 5% disk left
you also can check lsof, what files used by ES, and/or find to find the modified files from the last few hours.
using [1] data paths, mounts [[/ (rootfs)]], net usable_space [887.5mb], net total_space [49.9gb], spins? [unknown], types [rootfs]
Maybe the elastic cant write another (not data) file.
Second, (not related)
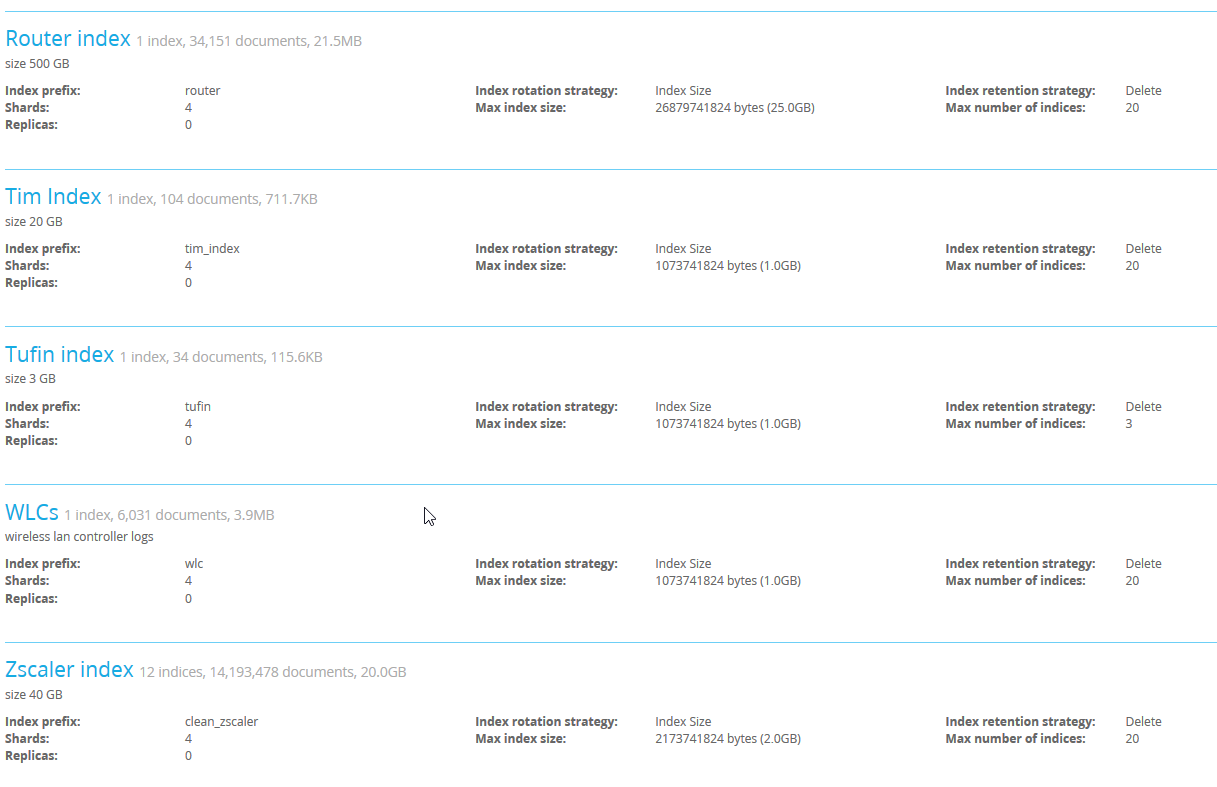
As far as I know, the ES recommendation for shard size is 20-40GB/shard. I suggest decrease the shards number for small indices and/or change retention policy (eg. 20GB max, 30 pcs -> 40GB, 15 pcs)
You have 6 servers, are you sure you don’t need to use replicas?
my shards are around 12 gb max.
and the writing of the files were all related to data files, not another file like logs or something else…
naturally related to the isolated space that i have only for logs and data files…