Hey there, the short story is no–you’re not just able to add a node and expect that the cluster will return to a healthy state. The reason being is that the shards present on the node that died are gone forever, meaning that you’ll forever have an incomplete dataset. Elasticsearch isn’t able to just magically recreate the data. The ONLY exception to this is if you decide to add replicas. Replicas are copies of shards that will be promoted if the primary shard is no longer active.
That said, I’d highly recommend reading over these two articles:
^ Those will help you better understand shards, replicas and how you can deploy Elasticsearch to be fault-tolerant.
Now to answer this:
If you have a 3-node cluster and 2 of them die, you’re going to be in a bad way. Again, adding more nodes won’t solve the issue if you don’t have replicas as a part of your sharding strategy within Graylog. But even then, you’d have to have multiple replicas as part of your index set. Without replicas, you can’t hope to ever bring the cluster back into a healthy state.
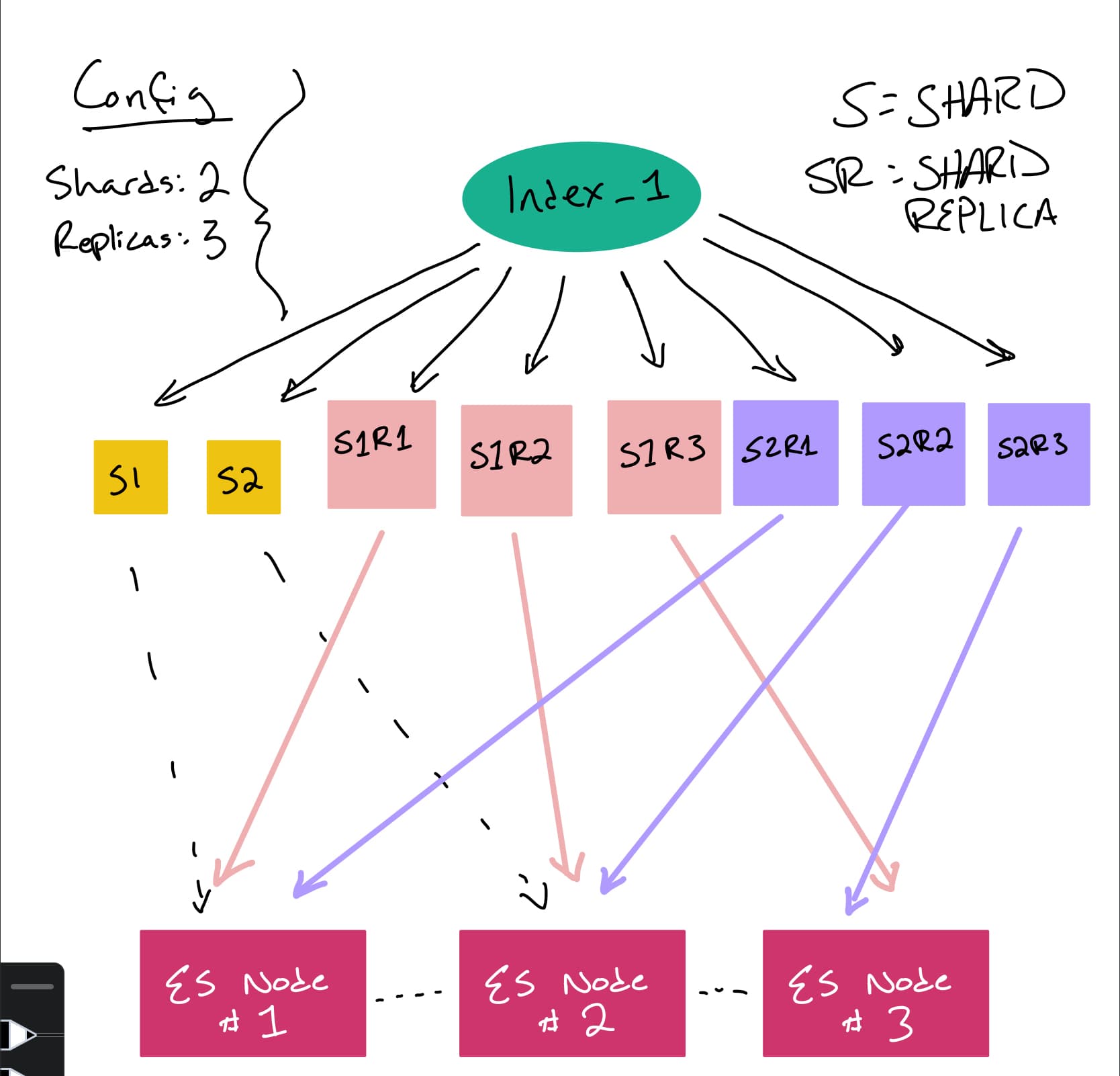
Let’s use this as an example: You create an index set with 2 shards and 3 replicas for your 3 node cluster. That would look like this:
So for each shard, you’d have a copy of the data on a node. Now, in the event of failure, those replica shards would be promoted to primary shards, meaning that the data is still present:
But what this also means is that the cluster would create the shards on the remaining node. So you’d have to have the available disk, cpu and RAM overhead available on that remaining node. Keep in mind that this is only for a single index set. The more index sets you have, the more overhead you’ll have to have in order to support a failure scenario. Keep in mind that this also doesn’t take into account the following:
- The size of the data in each index and its component shards
- The resources you’ve allocated to Elasticsearch (heap is going to be of primary concern here)
- Your retention requirements
- How often you’re rotating your data.
With that in mind, you’ll want to also read up on these recommendations from Elasticsearch:
So take some time to read up on those links so you have a better understanding of sharding and how data is stored within Elasticsearch. This should help inform your architectural design as you deploy Elasticsearch.